Rakam now supports dbt Core as data modeling layer
Most business intelligence products in the market usually come with an embedded transformation engine that lets you structure the data in a way that you want to analyze. Let me start with how it works and later I’ll tell you why it’s not best practice to structure your data in BI tools today and how our dbt Core integration might be the solution:
Tableau has [Prep] and PowerBI has [Data Prep] as their transformation engine. They work in a similar way and let you ingest your data from your database to their internal storage engine so these tools can prepare the data for analytics. There are a few drawbacks of using these solutions:
- It’s hard to use the data outside of the BI tool once you start using their internal storage engines because the output data is not in your data warehouse anymore.
- You will feel vendor locked-in because there isn’t usually any easy way to migrate to another BI tool that has the same features and supports the same query language for transformation. You usually need to start from scratch in that case.
- Since you need to copy the data to your BI tool from your data warehouse, you need to update the data inside your BI tool every time you push new data to your data warehouse. It’s not an easy process so in most cases you end up analyzing outdated data.
With modern data warehouse solutions like Redshift, Snowflake, and BigQuery, luckily you don’t need to use embedded storage engines of third-party BI tools, they’re efficient enough to answer ad-hoc queries if your tables have less than a few billion rows. However; if your data is not clean or you need to do some transformation, you still need to materialize the data inside the data warehouse in order to be able to build ad-hoc dashboards and let your end-users run their ad-hoc queries.
All of these three data warehouses support materialized tables out of the box. If your data pipeline somehow needs to be structured around dependency trees and make use of incremental materialization features, they’re not flexible enough. That’s where dbt Core shines; you can build your data models, document and test them while collaborating with your team members easily. Looker is also one of the few business intelligence products that have a similar concept called Persistent Derived Tables but since you need to use their query language called LookML for the transformation, it doesn’t solve the vendor lock-in problem.
At Rakam, we have been also using dbt Core as a transformation engine in order to speed up the segmentation queries in our [materialize] feature and now we started to support dbt Core’s schema.yml files. We automatically create dimensions and relations from your column definitions, and synchronize the label & description automatically when you integrate your dbt Core repository with Rakam. There were a few missing pieces though, dbt Core doesn’t provide a way to define the measures and mappings. Luckily, it has a meta field that lets us define extra properties in order to make Rakam works as follows:
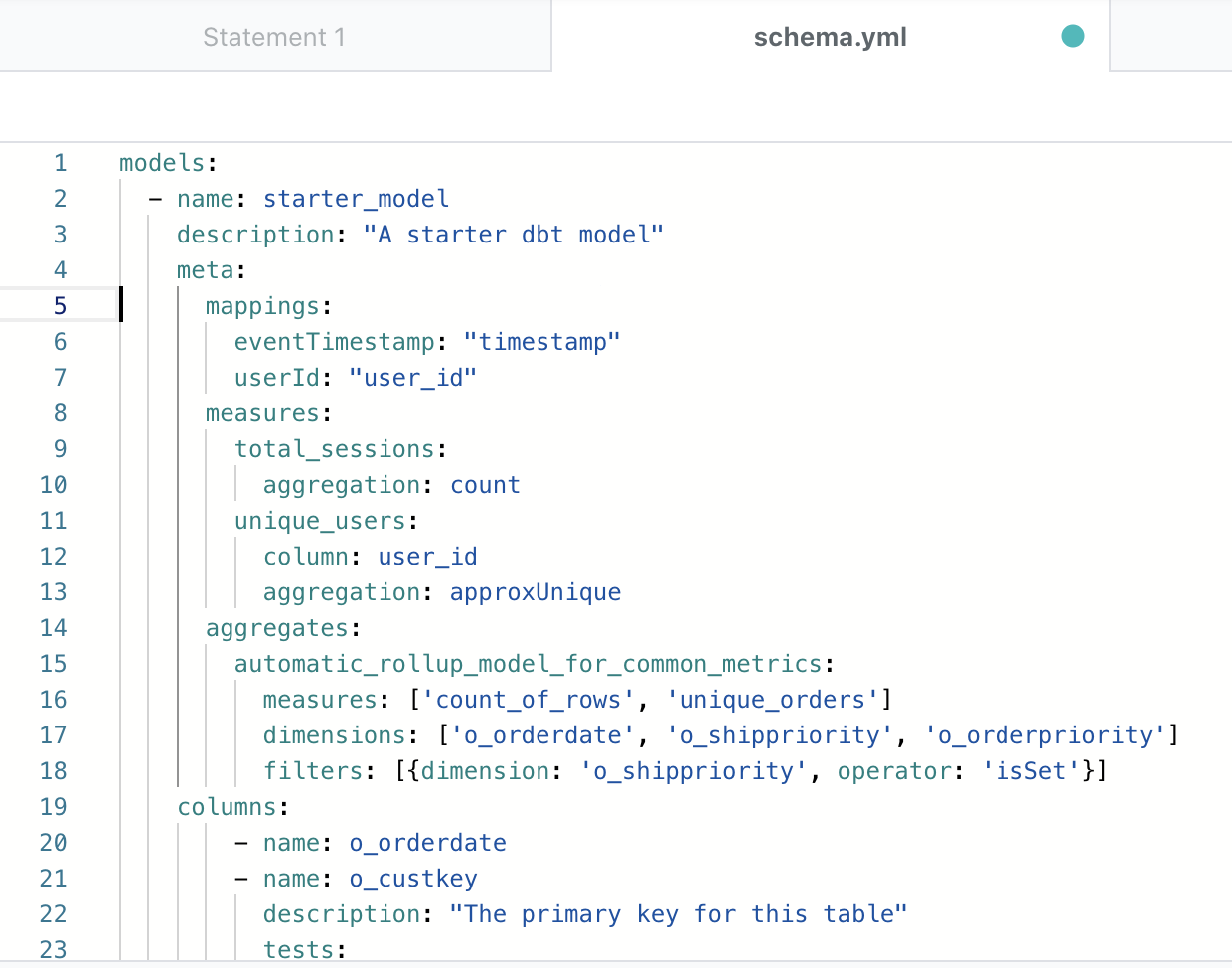
You can also use the same syntax in order to create models from your tables without using dbt Core’s transformation by defining the sql field under meta so you don’t need to learn our data modeling language in order to be able to use Rakam.
Our dbt Core integration solves the problems mentioned above. Since we will be using your dbt Core repository for all the models, it’s dead easy to use Rakam if you’re already familiar with dbt Core. We have seen that many companies use dbt Core and Looker together and try to keep their LookML definitions as simple as possible but we even remove the need for LookML-like language by leveraging your dbt Core models.
All the clean & transformed data will remain inside your data warehouse with that approach. Looking at the modern data stacks, the new trend is treating the data warehouses as the single source of truth. By applying this approach to your company:
- You will be able to take actions from your data by connecting your data warehouse to a reverse ETL tool such as Hightouch, Census. These tools let you sync your customer data to other tools you use such as CRM, marketing etc.
- You can use the data internally via SQL since the data will be available as database relations such as table and view.
How to get started with dbt Core + Rakam?
- Integrate your data warehouse with your credentials on Rakam.
- Connect Rakam to your dbt Core project through the “Integrate your GIT repository” button.
That’s all! All your dbt Core models will be automatically transferred to Rakam and you can run segmentation, funnel, and retention queries easily from your dbt Core models.
The feature is in beta now, please give it a shot and let us know if it’s useful to you!
P.S.: As dbt gets more traction, we will probably see a similar trend of dbt Core integration among reverse ELT tools (Census) and even ETL tools (Fivetran ) so if you’re planning to support dbt Core in your product and need metric definitions such as measures, we can collaborate on an open-source data modeling language. Just let me know on Twitter. 😉