Analyzing public BigQuery COVID-19 data with dbt and Rakam
In an effort to help combat COVID-19, Google has created a COVID-19 public datasets program to make data more accessible to researchers, data scientists, and analysts. This data is available in the BigQuery platform and can be reached by using this link. For my analysis, I have chosen to work with the covid19_open_data dataset since it is very rich containing more than 500 columns of data. More specifically, this dataset apart from providing information regarding the daily COVID-19 trends (e.g new confirmed cases, new people deceased), also provides country-specific information which gives the possibility to analysts to perform various sophisticated analyses.
Working with such a big and complicated dataset would be tedious and time-consuming but thanks to dbt and Rakam the whole procedure was made simpler. More specifically, dbt(data build tool) is an open-source command-line tool that enables data analysts and engineers to transform data in their warehouses more effectively. On the other hand, Rakam is a BI solution that enables product teams to get insights directly from their data warehouse. Since Rakam has integration with dbt in the modeling layer and BigQuery as a data warehouse connector, it made a lot of sense to me to use Rakam for my analysis because I didn’t have to move my data from BigQuery at all.
Model development with dbt
Firstly, after installing the open-source version of dbt, I followed the setting up guide provided by the dbt’s homepage during which I learned how to connect dbt with my BigQuery account and how to build and deploy my first dbt projects using VS Code. One of the many advantages of dbt is that it allows data analysts and engineers to transform their data in their data warehouses simply by using a combination of SQL and Jinja. For the most part, the developed models in dbt are written in pure SQL except for the ‘ref()’ calls written at the top of the models. ‘ref()’ is a function that dbt gives to users within their Jinja context to reference other data models. In particular, the ‘ref()’ function does two things: It interpolates itself into the raw SQL as the appropriate schema.table for the supplied model and it automatically creates a DAG of all the models in a given dbt project. In other words, it gives the possibility to its users to do powerful things such as run models in dependency order, parallelizes model builds and run subgraphs defined in its model selection syntax.
However, for this particular dataset, it was decided that none of these functions were needed since the analysis could be made by using a single dbt model. The model that I have created had the following form:

Simply explained, what this model does is that it calls all the columns from the public BigQuery COVID-19 dataset filtering them by ‘aggregation_level’ in order to grab only the values which correspond to country-level data, leaving out additional data which might correspond to cities or counties. Then, by running the dbt run command on my command line, I deployed this filtered data as a new view (or table) on my BigQuery account.
Setting up the analysis in Rakam
At this point is where Rakam came into the play. After creating a Github repository for my dbt files, I connected this repository to the Rakam environment with an SSH public key. This gave me the ability to manipulate my dbt files by using Rakam’s editor making the procedure simpler and faster. Furthermore, I connected Rakam with the newly uploaded COVID-19 dataset at BigQuery, and therefore I was ready to start building my analysis in the Rakam environment.
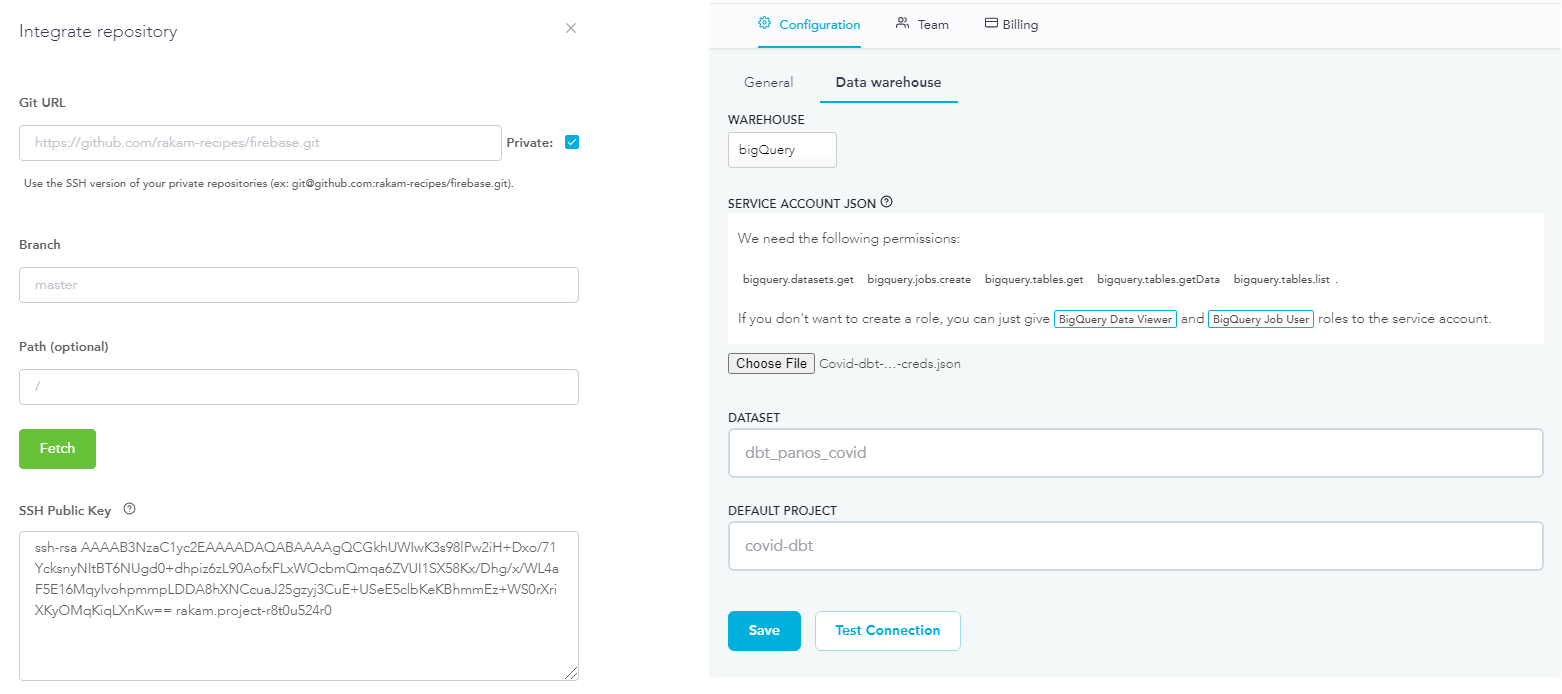
In order to start my analysis, firstly I needed to define the model’s metrics. This can be done in the dbt’s schema.yml file which is connected to the respective developed dbt model. Additional information about the model’s metrics can be found on this link while the documentation for the schema.yml file is found on this link. Generally, additional information regarding the aforementioned functions between Rakam and dbt can be found on this Rakam blog.
What I found particularly useful when I was developing my model is that Rakam gives the possibility to its users to use SQL expressions when defining their measures or dimensions. This gave me the ability to develop new measures/dimensions which were derived as calculations between other columns or even the ability to change the value names of certain columns when they didn’t offer appropriate information. For example, in one of my analyses, I wanted to create a chart indicating the level of imposed gathering restrictions by a certain country. However, the values provided by the dataset were integers ranging from 0-4 with each one of them indicating the different levels of the imposed gathering restrictions. I thought that this wouldn’t convey the information to the end-user appropriately and therefore I decided to convert these integers to strings that could provide a better description to users by using a CASE statement. This is depicted in the picture below along with the first 90 lines of the schema.yml file as a general example of how the different metrics are defined within the Rakam environment.
version: 2
models:
- name: covid
description: 'Covid19 Public Bigquery data'
columns:
- name: country_name
meta:
rakam.dimension:
column: country_name
type: string
- name: date
meta:
rakam.dimension:
column: date
type: timestamp
meta:
rakam:
label: Country Level Covid
name: test
dimensions:
restrictions_on_gatherings:
description: 'The level of restrictions regarding the amount of people allowed in the same place'
type: string
sql: CASE
WHEN restrictions_on_gatherings IS NULL THEN 'No restrictions'
WHEN restrictions_on_gatherings = 0 THEN 'No restrictions'
WHEN restrictions_on_gatherings = 1 THEN 'Low restrictions'
WHEN restrictions_on_gatherings = 2 THEN 'Moderate restrictions'
WHEN restrictions_on_gatherings = 3 THEN 'Increased restrictions'
WHEN restrictions_on_gatherings = 4 THEN 'Maximum restrictions'
END
category: country_imposed_restrictions
label: 'Gatherings Restriction Level'
school_closing:
description: 'Expresses the amount of closed schools to decrease the spread of the virus'
type: string
sql: CASE
WHEN school_closing IS NULL THEN 'Fully open'
WHEN school_closing = 0 THEN 'Fully open'
WHEN school_closing = 1 THEN 'Small amount closed'
WHEN school_closing = 2 THEN 'Moderate amount closed'
WHEN school_closing = 3 THEN 'Increased amount closed'
WHEN school_closing = 4 THEN 'Fully closed'
END
category: country_imposed_restrictions
label: 'School Closing Level'
income_support:
description: "The amount of financial support offered to a country's citizens due to lockdowns"
type: string
sql: CASE
WHEN income_support IS NULL THEN 'No support'
WHEN income_support = 0 THEN 'No support'
WHEN income_support = 1 THEN 'Low support'
WHEN income_support = 2 THEN 'Moderate support'
WHEN income_support = 3 THEN 'Increased support'
WHEN income_support = 4 THEN 'Maximum support'
END
category: country_supporting_measures
label: 'Income support to citizens'
debt_relief:
description: "The level of dept relied offered to a country's citizens due to lockdowns"
type: string
sql: CASE
WHEN debt_relief IS NULL THEN 'No debt relief'
WHEN debt_relief = 0 THEN 'No debt relief'
WHEN debt_relief = 1 THEN 'Low debt relief'
WHEN debt_relief = 2 THEN 'Moderate debt relief'
WHEN debt_relief = 3 THEN 'Increased debt relief'
WHEN debt_relief = 4 THEN 'Maximum debt relief'
END
category: country_supporting_measures
label: 'Debt relief to citizens'
measures:
covid_mortality_rate:
description: 'The percentage of people who died by covid in a country'
sql: 100*IEEE_DIVIDE(sum(new_deceased),avg(population))
category: important_calulated_indices
report:
suffix: '%'
COVID-19 Dataset Analysis in the Rakam environment
Finally, after defining all the required metrics in the schema.yml file, I was ready to start using Rakam’s segmentation feature to perform my first analyses.
 The picture above shows an example of how an analysis is made by using Rakam’s segmentation feature. An end-user can make an analysis by simply choosing the different measures, dimensions, and filters and then click on the ‘Query’ button. The system then develops the respective SQL code and provides the results in a tabular form. On top of that, the system gives you the ability to create different graphs by using the developed result table.
The picture above shows an example of how an analysis is made by using Rakam’s segmentation feature. An end-user can make an analysis by simply choosing the different measures, dimensions, and filters and then click on the ‘Query’ button. The system then develops the respective SQL code and provides the results in a tabular form. On top of that, the system gives you the ability to create different graphs by using the developed result table.
 The user by clicking on the SQL button on the top right corner can see the developed SQL code used to derive the results. This gives the ability to the user to check the correctness of the derived results.
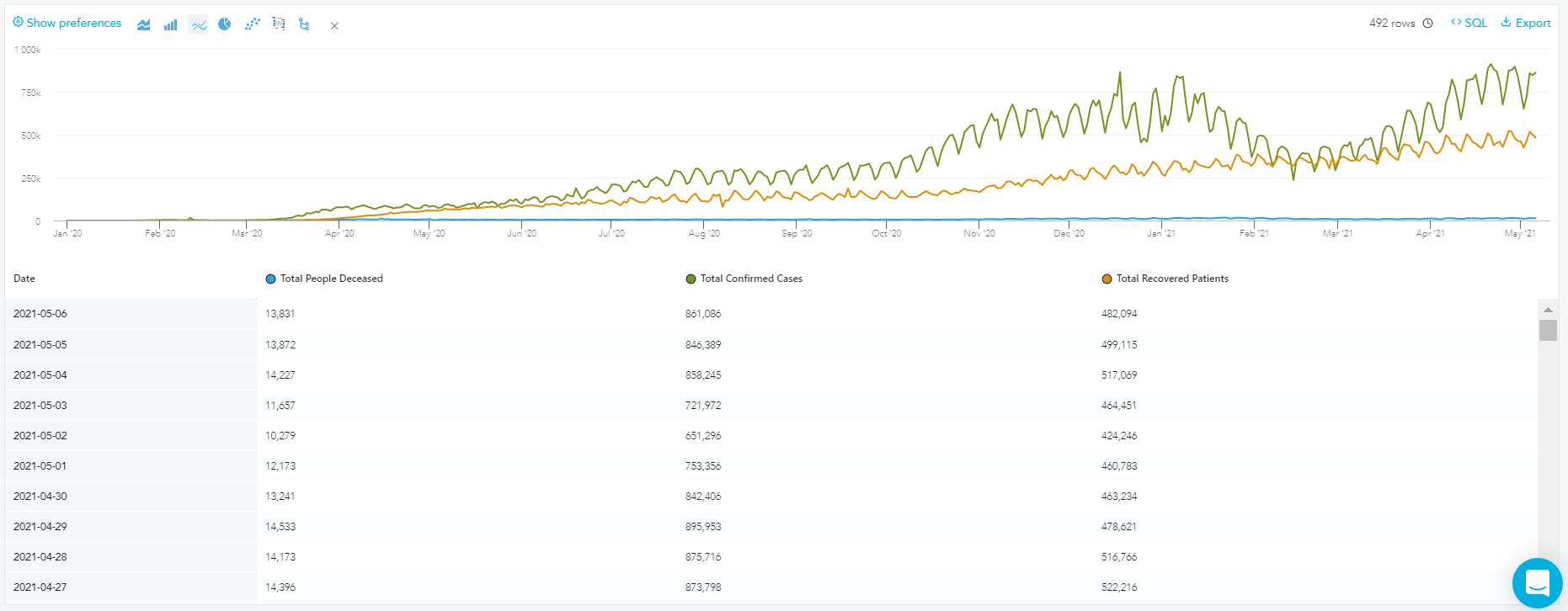
The user by clicking on the SQL button on the top right corner can see the developed SQL code used to derive the results. This gives the ability to the user to check the correctness of the derived results.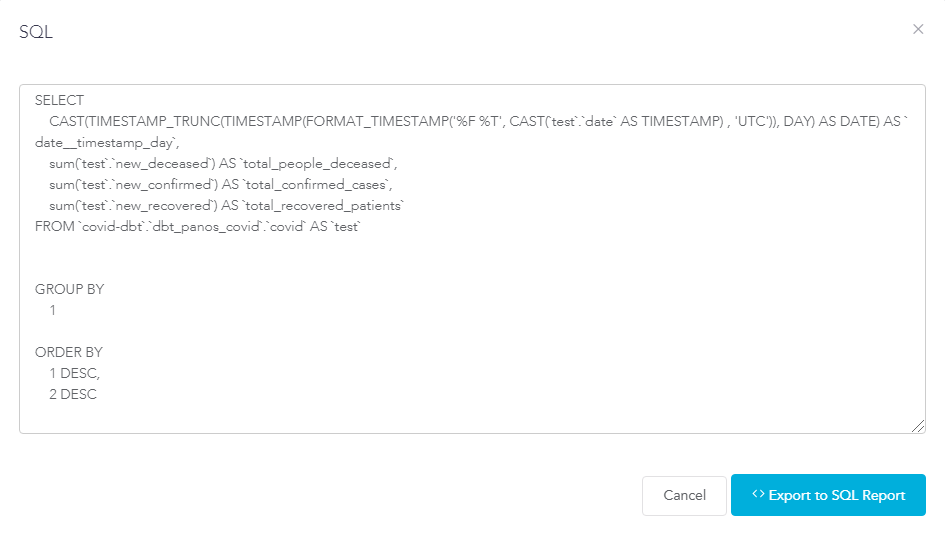 For my case, after developing a certain number of relevant reports I decided to pin them to dashboards. The first report I decided to add to my dashboard was a graph showing the daily trend of confirmed cases, deceased and recovered patients.
For my case, after developing a certain number of relevant reports I decided to pin them to dashboards. The first report I decided to add to my dashboard was a graph showing the daily trend of confirmed cases, deceased and recovered patients. As seen on the top of the pictures, the dashboard allows the user to filter the results for specific countries and date ranges giving the possibility for more specialized analyses. Some of the insights that I could derive from this graph was the impact that the different COVID-19 waves had as well as the increasing number of recovering patients which indicates that over time, medicine has found improved solutions to fight COVID-19.
As seen on the top of the pictures, the dashboard allows the user to filter the results for specific countries and date ranges giving the possibility for more specialized analyses. Some of the insights that I could derive from this graph was the impact that the different COVID-19 waves had as well as the increasing number of recovering patients which indicates that over time, medicine has found improved solutions to fight COVID-19.
As a second analysis, I decided to investigate the COVID-19 vaccinations. For this, I created a new measure that is called ‘Fully Vaccinated Percentage’ which is calculated as the total number of people fully vaccinated divided by the population of a country and then multiplied with 100 to convert it to a percentage value. I decided to use this measure because it gave me the ability to make comparisons between countries in terms of vaccination policies on the same scale. Additionally, I added the ‘Amount of People Fully Vaccinated’ and the ‘Total Vaccine Doses Administered’ columns in the analysis to give the reader a better view of the number of vaccinations in different countries.
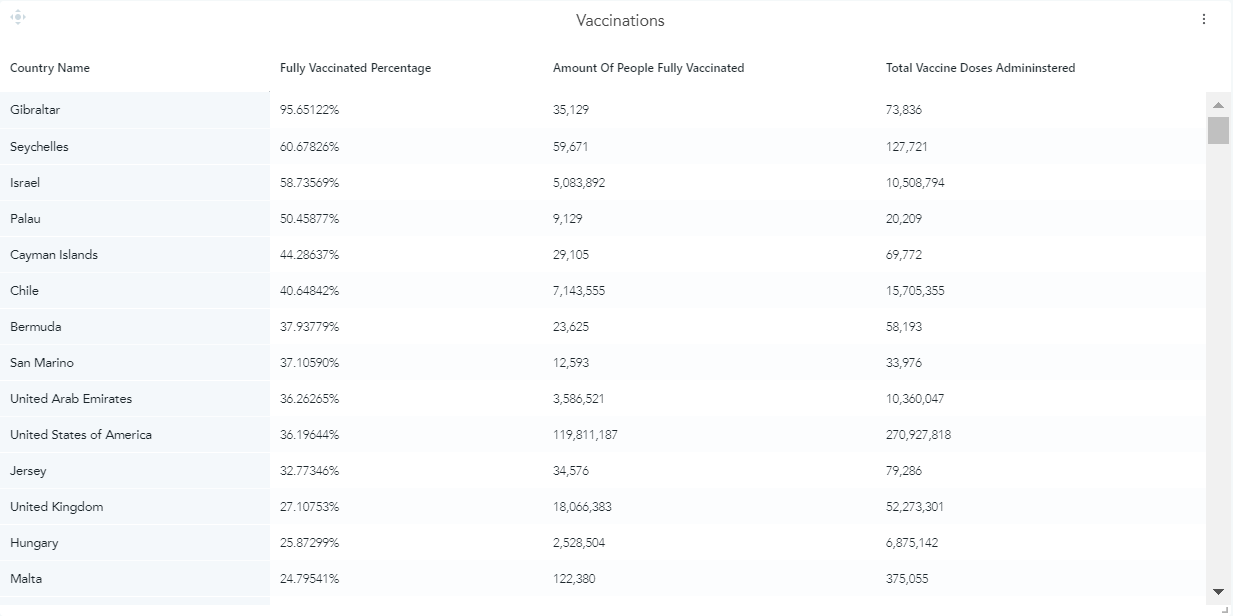
By looking at the graph above, we get the insight that countries with relatively low populations have high percentages of vaccinations. However, what is interesting about the results for Israel, the United Arab Emirates, Chile, and the US is that they seem to have high percentages of vaccinations despite their higher levels of population.
For my next analysis, I wanted to compare the lethality that COVID-19 had by gender.
We can see in the graph that COVID-19 had greater lethality in male patients. However, I was not able to understand the reason behind this since several different factors could contribute to such a result.

Furthermore, one of the analyses that I did included the investigation of the effectiveness of different country health systems. To investigate this metric I created a new measure which was called ‘Deaths To Confirmed Ratio’. This metric was calculated by dividing the total number of deaths due to COVID-19 with the total number of confirmed cases for each country. In other words, this metric indicated the capacity of different country health systems to help their COVID-19 patients survive. Then I coupled this metric in the same table with other relevant metrics such as ‘Nurses Per 1000 People’ and ‘Health Expenditure’ in order to get a broader view of the different country health systems.
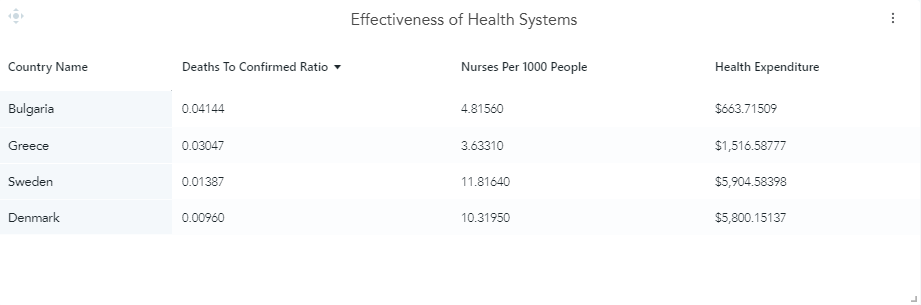 For my analysis, I chose two northern European countries (Sweden and Denmark) and two southern European countries (Bulgaria and Greece). The insights that I was able to get from this analysis included that both Bulgaria and Greece due to the lower investment in their health systems resulted in significantly higher numbers of deaths due to COVID-19 in comparison with Sweden and Denmark which made greater investments in their health system.
For my analysis, I chose two northern European countries (Sweden and Denmark) and two southern European countries (Bulgaria and Greece). The insights that I was able to get from this analysis included that both Bulgaria and Greece due to the lower investment in their health systems resulted in significantly higher numbers of deaths due to COVID-19 in comparison with Sweden and Denmark which made greater investments in their health system.
Additionally, in one of my analyses, I wanted to investigate if there is any correlation between smoking and COVID-19 lethality. To do that, I created a measure named ‘Covid Mortality Rate’ which simply indicates the percentage of a country’s population that died from COVID-19.
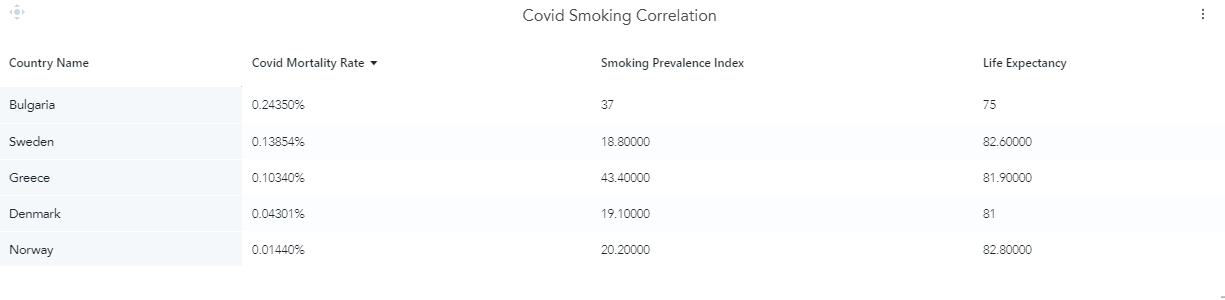 For this analysis, I chose some countries with high smoking prevalence index (Greece and Bulgaria) and I compared them with countries with relatively low smoking prevalence index (Sweden, Denmark, and Norway). By looking at the table above, we can see that there is some kind of correlation with the number of deaths and smoking when we compare Greece and Bulgaria with Denmark and Norway. However, this correlation doesn’t apply to Sweden since, despite its low smoking prevalence rate, the COVID-19 mortality rate was higher. Therefore, I concluded that several factors need to be considered when investigating correlations for the COVID-19 mortality rate (e.g. imposed restrictions, the effectiveness of health systems).
For this analysis, I chose some countries with high smoking prevalence index (Greece and Bulgaria) and I compared them with countries with relatively low smoking prevalence index (Sweden, Denmark, and Norway). By looking at the table above, we can see that there is some kind of correlation with the number of deaths and smoking when we compare Greece and Bulgaria with Denmark and Norway. However, this correlation doesn’t apply to Sweden since, despite its low smoking prevalence rate, the COVID-19 mortality rate was higher. Therefore, I concluded that several factors need to be considered when investigating correlations for the COVID-19 mortality rate (e.g. imposed restrictions, the effectiveness of health systems).
Finally, I wanted to investigate how effective the restrictions imposed by different countries in reducing the COVID-19 death toll were. For my analysis, I chose as a country of interest Sweden because it imposed relatively milder measures compared to other countries.

In the graph above, the vertical axis depicts the weekly number of deaths due to COVID-19, while with different colors are depicted the different levels of country restrictions imposed by Sweden. We can see that after the deaths during the COVID-19 waves started to increase, Sweden decided to increase the level of restrictions and this resulted in the slowly declining death toll. However, it should be mentioned that several factors could have contributed to this result.