Collect customer event data the hassle-free way
Rakam API is an open-source project the allows you to collect customer event data from your websites, mobile apps (Android, iOS etc.) and servers, enrich and store it in your data warehouse
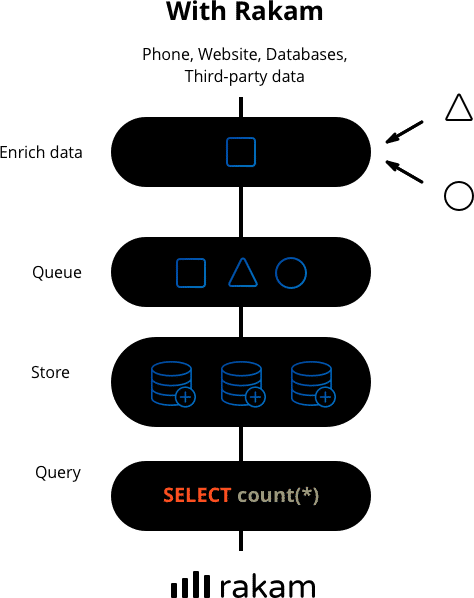
GitHub Documentation Trusted ByHow Rakam API Works
The API is developed with Java 8 and Netty and it's highly optimized for the API requests. It's battle-tested in product environments with 30B events per month with only 2 servers.
The API server requires you to set the configurations via config.properties file and you define all the enrichment, sanitization, and target database option in this file. You can even develop your own modules using ServiceLoader mechanism
The API works similar to SaaS product analytics tools, you send your event properties and the system automatically generates the schema on the fly. It's easy as using Google Analytics.
Your data, your rules
You will be installing the API on your servers that we don't have any access to. You can use the event data for product analytics, recommendation system or any in-house project later on.
One-click install with Terraform
We use Kubernetes with Terraform templates and we provide one-click installers for AWS and Google Cloud.
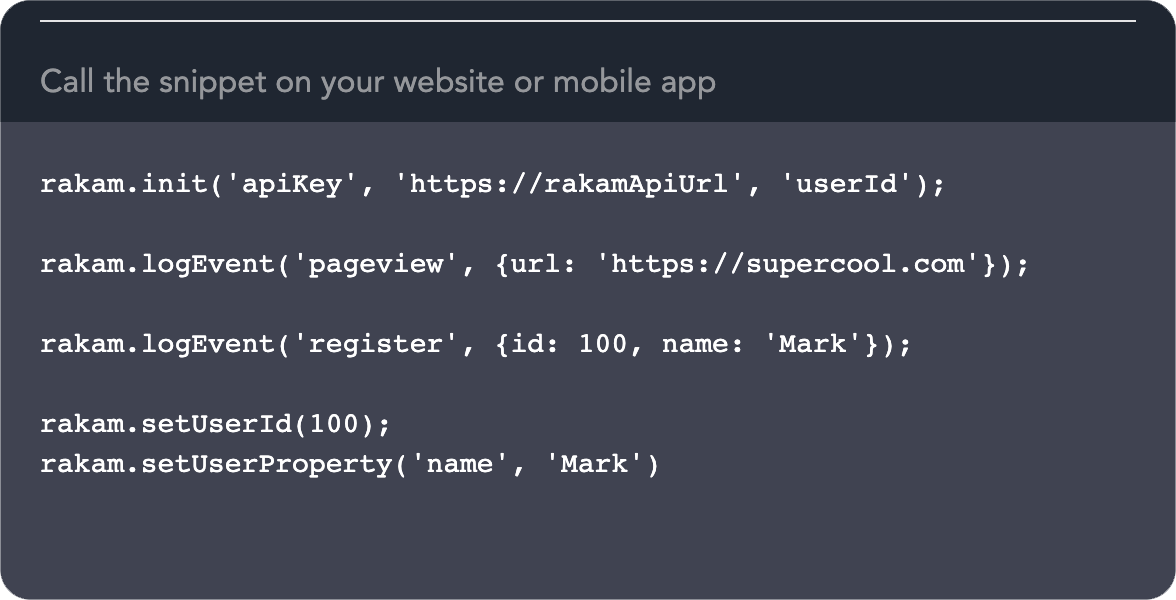
How SDKs work
We provide SDKs for Android, iOS and web platforms. The SDKs automatically enrich the data depending on the platform and send the data to your Rakam API.
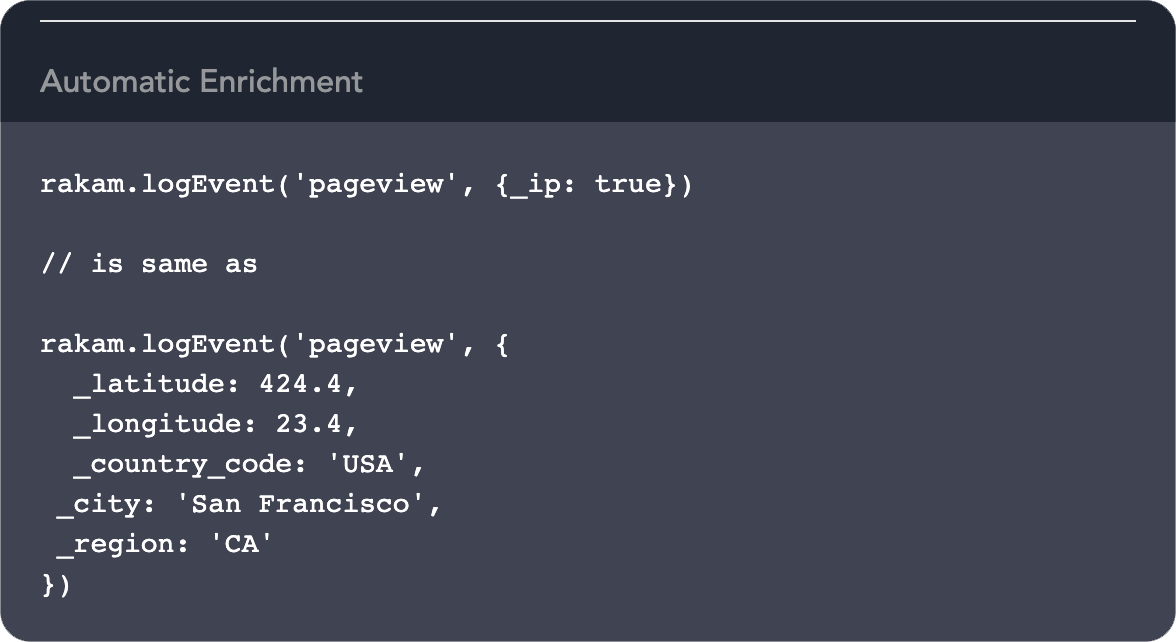
Enrich data in real-time
Rakam API will automatically enrich your customer data with
location, referrer and device information in API.
The SDK has in-built properties such as advertisement id in mobile
devices or the URL in websites.
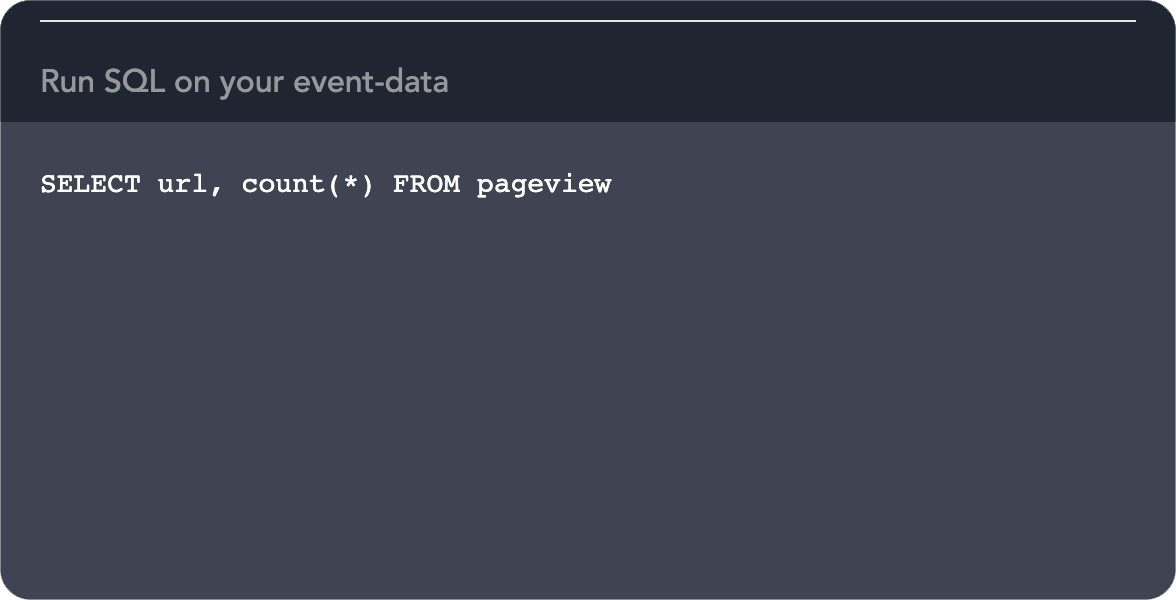
SQL for everything
You can either ingest the data into your Postgresql database or Snowflake cluster that horizontal scales easily. Then, run SQL queries on your event-data using the schema sent from your SDKs.
Deployment Types
PostgreSQL
It's the easiest way to start using Rakam. The API server enriches, sanitizes the data and INSERT into Postgresql in real-time. We make use of partitioned tables and BRIN indexes in order to leverage analytical features of Postgresql. This deployment type is scalable if you have less than 100M events per month because Postgresql is not horizontally scalable.


Snowflake
Snowflake based solution makes use of a distributed commit log (we support for Kafka, Kinesis and Google PubSub), a distributed storage system (we support S3 and Google Storage) for storing raw event data and Snowflake cluster if you need SQL access. Since it's horizontally scalable, it's the big-data solution that supports more than 100M events per month.
Compare to other solutions
We believe in using the right tool for the right technology. Here is the comparison matrix for similar solutions:
| Devops | |||
| Installation | It has the Terraform installer for AWS and Docker Compose that allows you to install it on your cloud. You enter the variables for your workload depending on your throughput and it setups the resources for you. | It supports AWS, Google Cloud, and Azure. You should go through the Snowplow documentation and setup the resources manually if you want to install it on your own. Otherwise, Snowplow offers consultation services for setting up the resources for you. | Since it's a SaaS, you register on Segment.com and create a tracker using their interface. |
| Maintenance | It uses Kubernetes under the hood and make use of Cloudwatch for scaling the cluster automatically in AWS. | The enterprise package (Snowplow Insights) has in-built alarms that scales the cluster. You need to setup the alarms in open-source version yourself. | No maintenance required. |
| High Availability | The Kubernetes cluster makes use of multiple availability zones within the region by default for performance reasons, it can also span across multiple regions for high availability. | It depends on the Collector that you use. The most reliable option is the Cloudfront tracker that depends on the managed AWS service thus doesn't require any servers. | No option provided. |
| Scalability | It scales horizontally and tested on 40B events per month and up to 2000 event types in production. It uses horizontal scaling, there is no limit in theory. | It scales horizontally and probably well-tested more than Rakam API since it's more popular. | No option provided. |
| Data Collection | |||
| Scalability | It's available in Web, iOS, amd Android platforms. See the documentation here for the details. It also provides an API for collecting data from third party and backend services. | It's available in many different languages and platforms. See the documentation for details. | In addition to the mobile and web platforms, it supports hundreds of sources including marketing and CRM tools. See the documentation. |
| Custom Events | Automatic schema discovery by inferring the values. We also have Taxonomy feature for validating and controlling the schemas. see docs | You need to define the schema in integration phase. see docs | Automatic schema discovery by inferring the values. It also has Segment Protocol for controlling the data flow. |
| User Attributes | See Docs | See Docs | |
| Enrichment |
Most common
pre-built enrichment
types like Geo Mapping, User Agent and Sessionization etc. In
addition to that
custom module SPI for
writing enrichments via Java and Javascript. We're in favor of ELT since it's easier to maintain. (Transforming the data in the data warehouse) | Many pre-built enrichment integrations. see docs | It does not provide any enrichment in the event data. |
| Customization |
We have an opinionated way to collect the data and only support 2
deployment types for simplicity. For > 10M events / month, use Postgresql.For > 10M events / month, use S3 target and connect to Snowflake. | It supports many different backends from Elasticsearch to BigQuery, S3, Redshift and Postgresql. It also have many different collectors for different use-cases. It might be a better solution is need more than "collecting raw customer event data". | It does not provide any customization, instead all the things work in plug/play manner. |
| Latency | By default, it's 5 minutes. The big part of the latency comes from Kinesis consumer to S3 target because we write the data in batches for performance reasons. | It's 45 - 80 minutes. It's because it relies on Cloudfront. See the documentation. for details. | At least 2 hours. Segment syncs the data as a separate process and you can configure it at least 2 hour intervals. |
| Best for event analytics that have many custom events | Best for pageview (click-stream) and enterprise-level analytics that have custom use-cases. | Best solution if you don't have a data team and need any customization. | |